Машинное обучение - подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться. Различают два вида обучения:с учителем и без учителя.
В первом случае имеется множество объектов и множество возможных ответов. Существует некоторая зависимость между ними, но она неизвестна, известна лишь совокупность прецендентов - пар "объект, ответ", называемых обучающей выборкой.
На основе этих данных и требуется восстановить зависимость, то есть построить алгоритм, способный для любого объекта выдать достаточно точный ответ.
Во втором же случае изучается шировкий класс задач обработки данных, в которых известны только описания множеств объектов и требуется обнаружить внутренние зависимости, существующие между объектами.
Самыми распространенными задачами для такого обучения являются кластеризация, поиск ассоциативных правил и т.п.
Рассмотрим основные виды задач:
Рассматривать все задачи будем на известном датасете "Титаник"
Для начала рассмотрим регрессию.
Под регрессией подразумаевается метод моделирования измеряемых данных и исследования их свойств. Данные состоят из пар значение зависимой переменной и независимой переменной.
Регрессионный анализ используется для прогноза, анализа временных рядов, тестирования гипотез и т.п.
Рассмотрим простейший пример: линейную регрессию.
В данном случае, y - переменная, которую нам нужно предсказать,w - некоторый весовой коэффициент, x - значение признака, - аддитивная случайная величина с нулевым мат. ожиданием.
На примере наших данных, нужно предсказать возраст, основываясь на таких признаках, как пол, номер каюты и т.п.
import pandas as pd DataFrame=pd.read_csv('train.csv') DataFrame.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | NaN | S |
from sklearn.linear_model import LinearRegression as LR regr = LR() regr.fit(data_x, data_y) data_y_nan = regr.predict(data_x_nan)
Код выше позволяет предсказать значение возраста по значению других критериев. Конечно, необходимо произвести предобработку данных, прежде чем передавать их в модель, так как регрессия работает только с числами.
Как определить, насколько хорошо работает наша модель? Очень просто!
Для этого вводят метрику качества. В случае с регрессией, отлично подходит среднеквадратичная ошибка. Рассмотрим график.
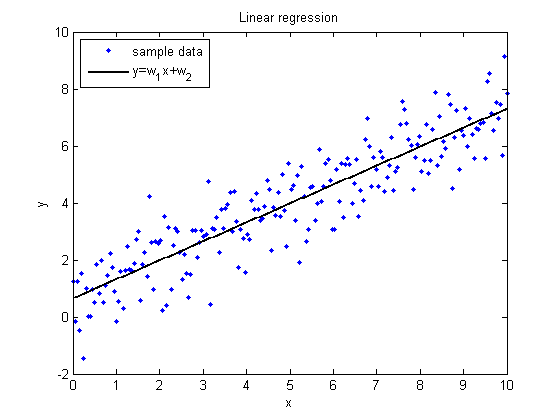
Для ее нахождения необходимо найти квадрат разности каждого предсказанного значения и истинного значения, после чего все это складывается и делится на количество объектов.Чем меньше данное значение, тем лучше.
Далее рассмотрим классификацию.
Классификация - один из разделов машинного обучения, посвященный решению следующей задачи:
Имеется множество объектов, разделенных некоторым образом на классы. Задано множество объектов, для которых известен класс, к которому они относятся, для остальных объектов принадлежность неизвестна.
Классифицировать объект - значит, указать номер класса, к которому относится данный объект. Подобные задачи также называют задачами дискриминантного анализа.
В рамках данной задачи рассмотрим метод LogisticRegression.
Преимущества этой модели в ее простоте и использовании логистической функции.
Логистическая регрессия используется для предсказания вероятности возникновения некоторого события по значениям признаков. Для этого вводится некая переменная, называемая зависимой, которая принимает, как правило, одно из двух значений: 0, если событие не произошло, и 1, если событие произошло.
Рассмотрим график логистической функции :
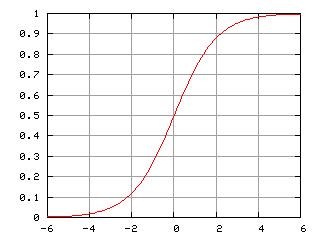
Исходя из этого графика, если значение у>0.5, то объект относится к первому классу, иначе, к нулевому. В нашей задаче, это означает, выжил человек или нет.
alg_log = LogisticRegression(random_state=1) scores = cross_val_score(alg_log, train_data_scaled, train_data_munged["Survived"], cv=cv, n_jobs=-1, scoring=linear_scorer) print("Accuracy (logistic regression): {}/{}".format(scores.mean(), scores.std()))
Используя данный код, получим необходимые нам метки классов.
Accuracy (logistic regression): 0.806958473625/0.0156323100754
Исходя из значения метрики качества, модель обучилась достаточно неплохо.
Последней задачей, представленной в данном разделе, является кластеризация.
Кластеризация(кластерный анализ) - задача разбиения исходной выборки на непересекающиеся множества, называемые кластерами, так,
чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно различались.
Входными данными, как правило, является признаковое описание, причем, признаки могут быть как числовыми, так и нечисловыми.
Пусть - множество объектов,
- множество номеров кластеров. Задана функция расстояния
Имеется конечная выборка . Требуется разбить данную выборку так, чтобы каждый объект из кластера был близок по метрике
, а объекты из других кластеров существенно отличались. При этом каждому объекту приписываеттся конкретное значение класса.
Алгоритм кластеризации - функция, которая для любого объекта определяет принадлежность к кластеру. Множество , при этом, чаще всего неизвестно заранее и ставится задача определить оптимальное количество кластеров по тому или иному критерию.
Кластеризация(обучение без учителя) отличается от классификации(обучение с учителем) тем, что метки исходных объектов не заданы.
Решение задачи кластеризации принципиально неоднозначно:
Рассмотрим действие такого алгоритма на примере:
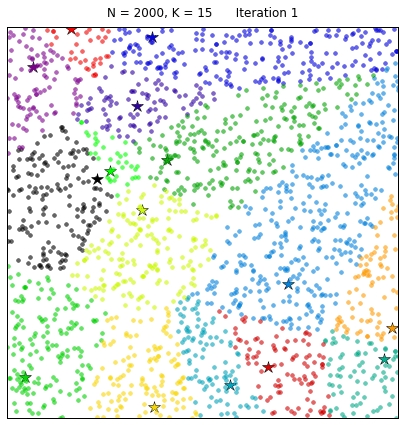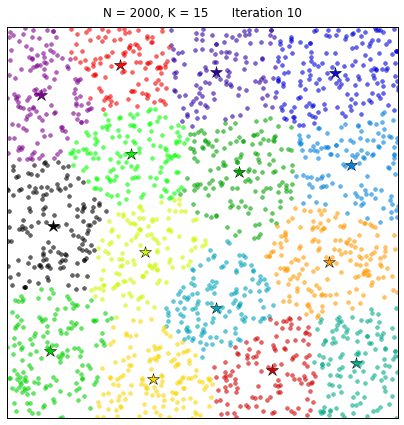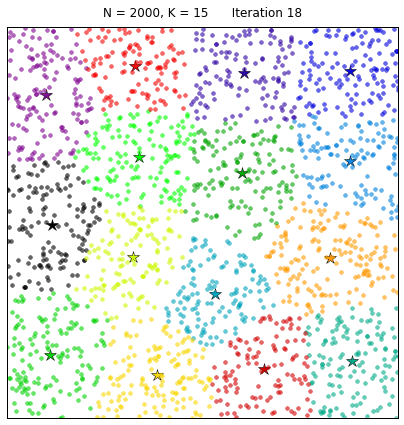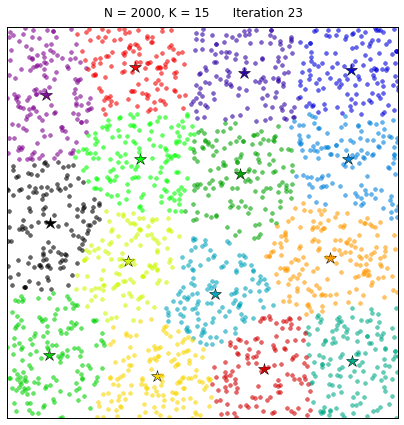
Естественно, на данных задачах не кончается область машинного обучения, однако, это некий базис, с которого стоит начать.
На главную